

W nowym Google Search Console pojawiły się ciekawe raporty wspierające proces analizy efektywności indeksowania strony. Mieliśmy okazję ostatnio audytować serwis, który dopiero niedawno został uruchomiony i widać, że jego zindeksowanie jest dość problematyczne. Wykorzystam to, aby pokazać kilka nowych statusów dostępnych w konsoli Google.
Spis treści
Raport o stanie indeksu
Raport stan indeksowania pokazuje dane zarówno w postaci wykresu, jak i w formie list (ułatwiających późniejsze rozwiązanie problemów).
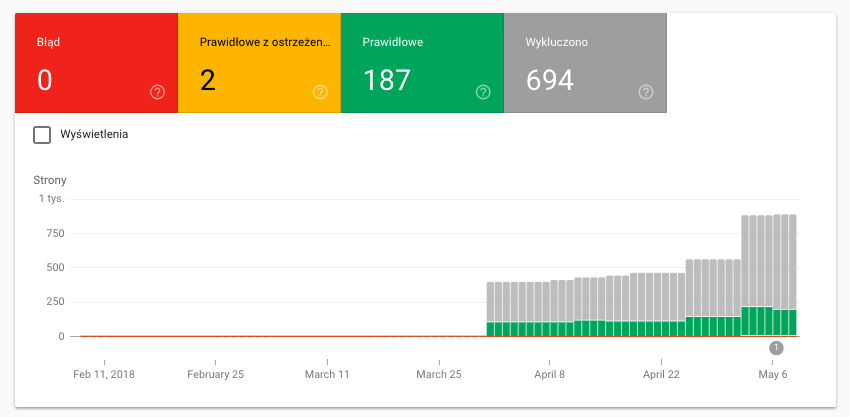
Wykres wyraźnie pokazuje proporcje między poszczególnymi statusami (Błąd / Prawidłowe z ostrzeżeniem / Prawidłowe / Wykluczono) w ujęciu czasowym. Od początku rzucać się w oczy może rozróżnienie między Błąd i Wykluczono. To właśnie Wykluczono (szare słupki na wykresie) jest moim zdaniem najciekawszym statusem, ale o tym zaraz.
Szukasz usług SEO?
Na wykres można nałożyć jeszcze wykres widoczności (Wyświetlenia) w Google:
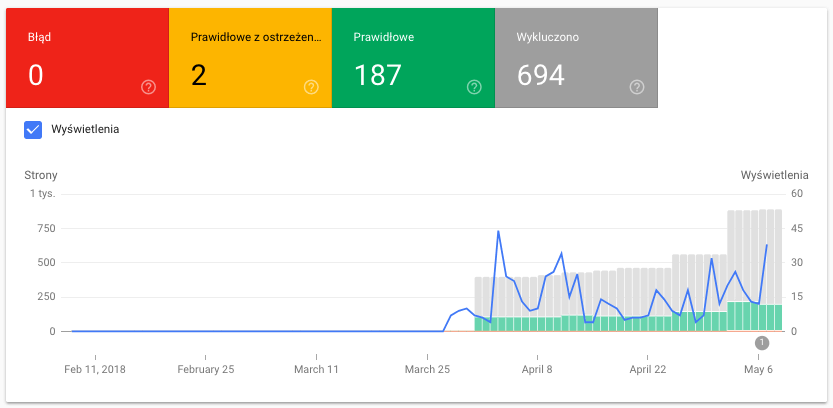
Muszę przyznać, że mi osobiście bardzo podoba się taki sposób wizualizacji danych. W porównaniu do starego GSC jest to zauważalny progres. Długo przyszło nam na to czekać 😉
Zaznaczenie wszystkich opcji wykresu(domyślnie zaznaczony jest tylko element „Błąd”) spowoduje także wyświetlenie poszczególnych segmentów w liście w dolnej części raportu.
Statusy w raporcie nowego GSC
Lista jest rozbita na kilka kolumn: stan, przyczyna, weryfikacja, trend, strony. Dzięki temu możemy poznać problem, jego skalę i postęp w jego rozwiązywaniu.
Poniżej przykład z audytowanego przez nas sklepu internetowego, w którym występuje dość szerokie spektrum różnych stanów indeksowania:

Dotychczas w analizie stron adresy URL były dzielone głównie na:
- zindeksowane
- celowo zindeksowane
- zindeksowane przez pomyłkę (gdy zapomnieliśmy dodać noindex do zasobów, które nie mają być dostępne w Google)
- niezindeksowane
- celowo (bo chcemy je blokować)
- niezamierzenie (no i tu głównie jest problem – czemu nasz content nie jest dostępny w Google)
Teraz możemy lepiej zrozumieć etapy i możliwe „perturbacje”. Może się okazać, że strona jest zindeksowana, mimo że blokujemy ją w robots.txt.
Efektywność indeksowania a dyrektywy dla robotów
To kolejny przykład na to, że samym robots.txt nie jesteśmy w stanie efektywnie zarządzać procesem indeksowania, a właściwym rozwiązaniem jest stosowanie równolegle dodatkowych dyrektyw dla robotów z poziomu poszczególnych URL. Robot może trafić do poszczególnych podstron z zewnątrz i nie zastosować się do robots.txt.
Dowiedz się więcej:
- Specyfikacje metatagu robots i nagłówka HTTP X-Robots-Tag w developers.google.com
- Specyfikacje pliku robots.txt w w developers.google.com
W przypadku przedstawionego raportu Google jasno informuje, że nie zindeksuje szeregu adresów URL, które pobrał, więc nie ma sensu umieszczać ich np. w sitemap.xml czy linkowaniu wewnętrznym (po co marnować crawl budget?!).
Google pobrał, ale nie zindeksował
Wśród zasobów, które Google pobrał, ale nie zindeksował, widzimy między innymi:
- strony pozornego błędu 404 (gdy użytkownik trafia na stronę, która nie istnieje, ale przeglądarka dostaje status 200: OK)
- URL, z którego ustawiono przekierowanie
- typowe błędy 404
- strony blokowane w robots.txt lub za pomocą meta tagu robots
Ciekawe są jednak przypadki bardziej enigmatyczne jak Pobrano, ale jeszcze nie zindeksowano, Nieprawidłowość związana z indeksowaniem, czy duplikat strony, który nie zawiera tagu strony kanonicznej. Google jak zwykle postarało się o jasne komunikaty 😉
Na szczęście na stronach supportu już pojawiły się stosowne objaśnienia.
Pobrano, ale jeszcze nie zindeksowano:

Nieprawidłowość związana z indeksowaniem:

Duplikat strony, który nie zawiera tagu strony kanonicznej:

Każdy z tych przypadków jasno pokazuje, że tzw. technical SEO będzie zyskiwać na znaczeniu.
Kolejny przykład pokazuje, że Googlebot niekoniecznie musi stosować się do tego, jakie damy mu instrukcje w rel=”canonical”:

Co Google tłumaczy następująco:

SEO: Optymalizacja pod kątem wydajności crawlowania
Google ma ograniczone zasoby. To ich główny koszt. Dlatego też efektywna komunikacja z robotami może stanowić klucz, nie tyle w pozycjonowaniu strony, co w ogóle w procesie jej indeksowania. Google nie będzie marnować zasobów na twoją stronę (crawl budget), jeśli w danej tematyce ma dostatecznie dużo alternatywnych witryn, które stanowią dostatecznie wartościowy zasób dla użytkownika, a mogą podlegać efektywniejszemu crawlowaniu i indeksowaniu.
W tym kontekście zagadnienia takie jak dbanie o szybkość witryny (i nie mam tu na myśli samego wyniku PageSpeed Insights, a wszystkie kwestie – związane z efektywnością odpowiedzi serwera, ładowania above the fold, czy też wykorzystania skryptów wpływających na renderowanie, kompresją zasobów), cykliczne badanie strony własnymi crawlerami, zarządzanie linkowaniem wewnętrznym, przygotowanie poprawnej mapy XML, będą zyskiwać na znaczeniu.
Nie ze względu na jakiś tajny, nowoczesny algorytm bazujący na sztucznej inteligencji, a po prostu w wyniku faktu, że Google też musi oszczędzać zasoby.
źródło screenów wykresów: search.google.com
Omówienie raportu stan indeksu: https://support.google.com/webmasters/answer/7440203